You are here
MySQL Cluster - Cluster Ring-Replikation mit 2 Replikations-Kanälen
Wed, 2011-01-12 20:25 — oli
Dokumentationsfehler über
Vor ein paar Tagen hatte ich wieder einmal mit einer MySQL Cluster Replikation zu tun. Ich habe das schon eine Weile nicht mehr angelangt und war somit vorbereitet, wieder einmal ein paar Überraschungen zu erleben.
Diejenige, für welche MySQL Cluster - Cluster Ring-Replikationen das tägliche Brot ist, können diesen Artikel getrost überspringen. Alle anderen können möglicherweise von unseren Erfahrungen profitieren.
Wir hatten das folgende MySQL Cluster Konstrukt im Einsatz:
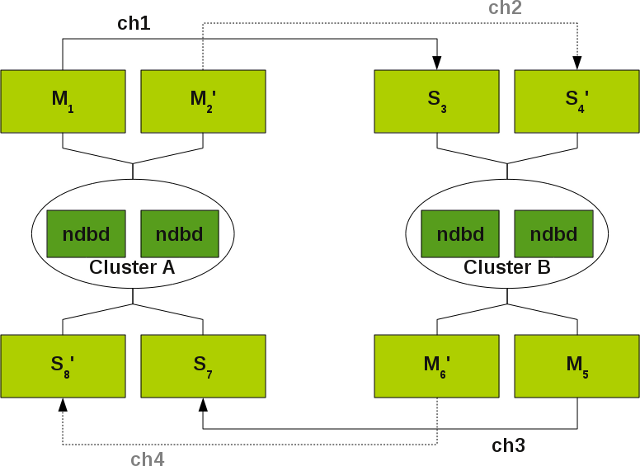
Mehr Informationen über solche Gebilde können in der MySQL Cluster Dokumentation gefunden werden.
Situationen welche zu einem Channel Failover führen:
Was sind die Problem, mit dem MySQL Cluster, welche zu einem Channel Failover führen:
- Der MySQL Master verliert die Verbindung zum MySQL Cluster (lost_event, gap).
- Der MySQL Master kann mit der Last auf dem MySQL Cluster nicht Schritt halten und verliert daher Events (gap). Ich bin wirklich etwas verwundert über das Argument in der Dokumentation [ 1 ], dass in einem solchen Fall ein Channel Failover durchgeführt werden kann oder soll. Weil, wenn der Master 1 mit der Last nicht mehr Schritt halten kann, warum soll es dann Master 2 noch können...?).
Was eine Lücke (gap / lost_event) ist, kann der folgenden Skizze entnommen werden:
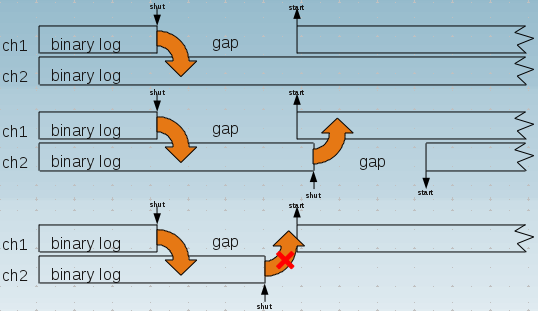
Wie ein solches System aufgesetzt wird, wollen wir hier nicht betrachten. Die Anleitung dazu können der MySQL Cluster Dokumentation entnommen werden.
Unsere Erkenntnisse
Unsere Erkenntnisse waren folgender Art:
Doppelte Primary Key Einträge
Wir erhielten einige doppelte Index Einträge für unsere AUTO_INCREMENT Primary Keys:
ERROR 1062 (23000): Duplicate entry '260' for key 'PRIMARY'
Der Grund dafür ist, dass wir ndb_autoincrement_prefetch_sz auf 256 gesetzt hatten, um eine bessere INSERT Performance zu erhalten.
Als Konsequenz erhält man, früher oder später, wenn man Daten in alle mysqld's auf beiden Clustern einfügt, einen Primary Key Konflikt.
Wir haben dieses Problem gelöst, indem wir die auto_increment_increment und auto_increment_offset Werte für die SQL Knoten auf beiden MySQL Clustern entsprechend gesetzt haben.
Empfohlene Channel Failover Methode funktioniert nur unter Last
Ein weiteres Problem, welches wir bereits vor langer Zeit bei einem anderen Kunden entdeckt haben, ist, dass das empfohlenen Channel Failover-Vorgehen [ 2 ]:
slave1> STOP SLAVE; slave1> SELECT MAX(epoch) AS latest FROM mysql.ndb_apply_status; master2> SELECT SUBSTRING_INDEX(File, '/', -1) AS master_log_file , Position AS master_log_pos FROM mysql.ndb_binlog_index WHERE epoch > <latest> ORDER BY epoch ASC LIMIT 1; slave2> CHANGE MASTER TO master_log_file='<master_log_file>', master_log_pos=<master_log_pos>;
nur funktioniert, wenn wir Last auf dem MySQL Cluster haben. Wenn wir gar keine Last haben, gibt diese Abfrage ein leeres Resultat zurück und es muss der Befehl SHOW MASTER STATUS dazu verwendet werden.
Dokumentationsfehler über log_slave_updates
Diese Situation haben wir fortwährend für Kanal ch2 und ch3 vom Cluster B auf den Cluster A wenn wir KEINE Last auf Cluster B haben und streng der Dokumentation gefolgt wird, wo für ein solches Gebilde gesagt wird: log_slave_updates DARF NICHT eingeschaltet (MUST NOT be enabled) [3] werden.
Ich habe dieses Problem mit ein paar Leuten diskutiert und bin zur Ansicht gekommen, dass die MySQL Cluster Dokumentation hier punktuell falsch ist. Der Master für eine 2 Cluster Replikation KANN log_slave_updates eingeschaltet haben und IMHO MUSS der Master einer 3 Cluster Replikation log_slave_updates eingeschaltet haben.
Aber trotzdem, wenn wir keine Last auf beiden Servern haben, müssen wir das Verfahren ändern um die korrekte Binary Log Position zu bestimmen, wenn wir den Kanal wechseln wollen. Das macht es etwas schwieriger wenn wir den Channel Failover automatisieren oder skripten wollen.
Leere Epochen
Früher, wenn ich mich recht erinnere, hat MySQL Cluster immer leere Epochen ins Binary Log geschrieben. Das hatte gewährleistet, dass immer eine gewisse Last auf den Kanälen geherrscht hat. Dann habe ich bei den MySQL Cluster Entwicklern reklamiert und diese haben dieses Problem behoben. Aber für die eben besprochene Situation wäre dieses Verhalten geradezu nützlich und würde Sinn machen. Also habe ich nach der ndb-log-empty-epochs Variablen Ausschau gehalten und gehofft, dass sie dieses Verhalten wieder ermöglicht. Aber irgendwie hat der MySQL Cluster für dieses Set-Up trotz der Verwendung dieser Variable keine leeren Epochen ans Binary Log gemeldet. Zumindest nicht in der kurzen Zeit, wo ich mich mit diesem Problem beschäftigt hatte.
Log_slave_updates wird auch durch den Binlog Injector Thread berücksichtigt
Eine weitere Erkenntnis mit log_slave_updates war, dass dieser Parameter entsprechend der Dokumentation, nur zum Zug kommt, wenn ein Slave auch als Master agiert [4]. Was heisst, dass er nur die Daten in sein Binary Log schreibt, wenn er die Daten direkt von seinem Master erhält. Es macht den Anschein, dass dies eine falsche Annahme ist. Ein Master scheint auch die Statements welche durch den Binlog Injector Thread [5] über den Cluster kommen, in sein Binary Log zu schreiben. Dies ist möglicherweise ein weiterer Dokumentationsfehler oder zumindest eine Dokumentationslücke.
Skip_slave_start sollte verwendet werden
Eine weiter Stolperfalle ist, dass ich vergessen habe, die Variable skip-slave-start zu setzen. Diese Variable sollte IMHO in einem solchen Set-up immer auf dem Slave gesetzt sein. Wenn ein Slave startet, kann er nicht wissen, ob er der aktive Channel sein wird oder nicht.
Zusammenfassung
- Überwache Deine Replikations-Kanäle.
- Nutze
auto_increment_incrementundauto_increment_offsetwenn auf beide MySQL Cluster gleichzeitig geschrieben wird oder vermeideAUTO_INCREMENT. - Verwende ein kluges Channel Failover Skript.
- Verwende
log_slave_updatesauf allen Mastern. - Verwende
skip_slave_startauf allen Slaves.
Das waren die Erkenntnisse unseres letzten Einsatzes mit MySQL Cluster Replikation und Failover Replikations-Kanälen. Wenn Sie weitere oder andere Erfahrungen gesammelt haben, wären wir froh, von Ihnen darüber zu hören.
Ein Skript zum automatisierten Failover der Kanäle kann unter Download gefunden werden.
Taxonomy upgrade extras:
- oli's blog
- Log in or register to post comments