Feed Aggregator
Scheint bereits im Juni letzten Jahre entschieden worden zu sein
Wie der Screenshot von GitHub zeigt, scheint diese Entscheidung bereits im Juni 2026 gefallen zu sein:

Taxonomy upgrade extras:
Categories:
MariaDB verkürzt Wartungszeitraum von 5 auf 3 Jahre
Irgendwie ist die Meldung an mir vorbei gegangen: MariaDB hat den Wartungszeitraum für die Long-Term Releases des MariaDB Community Servers von 5 auf 3 Jahre verkürzt. OK, ist ja nicht weiter verwunderlich, ich war ja gut einen Monat offline…
MariaDB Server LTS Release Wartungszeiträume
| Release | GA Datum | EoL Datum | Dauer |
|---|---|---|---|
| 12.3 | 28 May 2026 | Jun 2029 | 3 Jahre |
| 11.8 | 4 Jun 2025 | 4 Jun 2028 | 3 Jahre |
| 11.4 | 29 May 2024 | 29 May 2029 | 5 Jahre |
| 10.11 | 16 Feb 2023 | 16 Feb 2028 | 5 Jahre |
| 10.6 | 6 Jul 2021 | 6 Jul 2026 | 5 Jahre |
| 10.5 | 24 Jun 2020 | 24 Jun 2025 | 5 Jahre |
| 10.4 | 18 Jun 2019 | 18 Jun 2024 | 5 Jahre |
| 10.3 | 25 May 2018 | 25 May 2023 | 5 Jahre |
| 10.2 | 23 May 2017 | 23 May 2022 | 5 Jahre |
| 10.1 | 17 Oct 2015 | 17 Oct 2020 | 5 Jahre |
| 10.0 … |
Taxonomy upgrade extras: mysql, database, eol, support, mariadb, postgresql, percona,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Wie lädt man Daten am schnellsten in die Datenbank?
Beim letzten Kunden hatten wir wirklich ein paar spannende Fragen zu lösen! Insbesondere auch, weil die Datenbank nicht ganz klein war.
Hier kurz einige Eckdaten: CPU: 2 Sockel x 24 Kerne x 2 Threads = 96 vCores, 756 G RAM, 2 x 10 Tbyte PCIe SSD im RAID-10 und 7 Tbyte Daten, einige Tausend Mandanten, stark wachsend.
Der aktuelle Durchsatz: 1 M SELECT/min, 56 k INSERT/min, 44 k UPDATE/min , 7 k DELETE/min gemittelt über 30 Tage. Tendenz stark steigend. Applikation und Queries nicht durchgängig optimiert. Datenbank Konfiguration: “state of the art” nicht mit Benchmarks verifiziert. CPU-Auslastung ca. 50% im Schnitt, in der Spitze mehr. I/O System hat noch Luft nach oben.
Der Kunde sammelt Positions- und sonstige Gerätedaten ein und speichert diese in der Datenbank. Also ein klassisches IoT Problem (mit Zeitreihen, Index Clustered Table, etc.).
Die Frage, die er gestellt hat, ist: Wie kriege ich am schnellsten Daten von einer Tabelle (pending data, eine Art Queue) in eine andere Tabelle (final data, …
Taxonomy upgrade extras: postgresql, mariadb, mysql, insert, transaction, commit, multi-row insert,
MariaDB hat das Konzept des dynamisch konfigurierbaren Buffer Pools kaputt gemacht!
Problembeschreibung
MySQL hat mit 5.7.5 im September 2014 den dynamisch konfigurierbaren InnoDB Buffer Pool eingeführt (hier und hier):
The innodb_buffer_pool_size configuration option can be set dynamically using a SET statement, allowing you to resize the buffer pool without restarting the server. For example:
mysql> SET GLOBAL innodb_buffer_pool_size=402653184;
MariaDB 10.2.2 hat dieses Feature im September 2016 übernommen (Quelle):
InnoDB was merged from MySQL-5.7.14 (XtraDB is disabled in MariaDB-10.2.2 pending a similar merge)
Das Problematische ist einerseits, dass dieses Feature jetzt nicht mehr funktioniert wie bis anhin und nicht mehr funktioniert wie erwartet. Anderseits haben sie das Verhalten im Frühling 2025 innerhalb einer Major Release Serie (LTS) geändert, was meiner Meinung nach ein absolutes no-go ist (Quelle):
From MariaDB 10.11.12 / 11.4.6 / 11.8.2, there are significant changes to the InnoDB buffer pool behavior.
Und zudem ist die Beschreibung dazu recht dürftig (Quelle): …
Taxonomy upgrade extras: mariadb, innodb, buffer pool,
Wie viel Platz braucht NULL?
Beim letzten Beratungseinsatz beim Kunden, kam dieser freudestrahlend auf mich zu mit der Bemerkung: Er habe meinen Rat befolgt und sämtiche Primary Key Spalten von BIGINT (8 byte) auf INT (4 byte) geändert und das habe viel gebracht! Seine MySQL 8.4er Datenbank sei jetzt um 750 Gbyte kleiner geworden (von 5.5 Tbyte). Schön!
Und ja, ich weiss, dass wiederspricht den Empfehlungen einiger meiner PostgreSQL Kollegen (hier und hier). In der MySQL-Welt wird eher auf solche Dinge Wert gelegt (Quelle):
Use the most efficient (smallest) data types possible. MySQL has many specialized types that save disk space and memory. For example, use the smaller integer types if possible to get smaller tables
Zudem funktioniert InnoDB ein klein wening anders (Index Clusterd Table und Primary Key in allen Secondary Keys) als PostgreSQL (Heap Table, Indices mit Row Pointer (ctid)).
Aber das ist eigentlich nicht das Thema. Sofort im Anschluss kam er nämlich mit der Frage, ob das AusNULLen von Spalten vom Typ DOUBLE (8 byte, in …
Taxonomy upgrade extras: null, postgresql, mariadb, mysql, vacuum, optimize,
Jemand löscht meine Shared Memory Segmente!
Wenn wir mit PostgreSQL unter unserem myEnv arbeiten, kriegen wir regelmässig Shared Memory Segment Fehler. Beispiel:
psql: error: connection to server on socket "/tmp/.s.PGSQL.5433" failed:
FATAL: could not open shared memory segment "/PostgreSQL.4220847662":
No such file or directory
oder wir sehen ähnliche Meldungen im PostgreSQL Error Log:
ERROR: could not open shared memory segment "/PostgreSQL.4220847662":
No such file or directory
Weil ich ein MariaDB/MySQL Admin bin, kenne ich mich nicht so gut mit Shared Memory Problemen aus (MariaDB/MySQL arbeitet nicht mit Shared Memory). Zum Glück hat uns eine Suche im Internet auf eine Fährte geführt (Quelle). Dort wird vermerkt:
The documentation of systemd states that this only happens for non-system users. Can you check whether your “postgres” user (or whatever you are using) is a system user?
Linux System User
Zuerst musste ich mal herausfinden was ein System User unter Linux überhaupt ist. Eine Antwort habe ich hier …
Taxonomy upgrade extras: postgresql, shared memory, myenv, systemd,
CSV Dateien in die Datenbank laden
Kürzlich wollte ich für eine persönliche kleine Spielerei die Wohnorte der Vereinsmitlieder meines Vereins auf einer Karte darstellen (IGOC Mitglieder). Die Adressen der Vereinsmitglieder waren mir bekannt. Nicht aber die Koordinaten der Wohnorte.
Also machte ich mich auf die Suche nach den Koordinaten und wurde beim Bundesamt für Landestopografie (swisstopo) fündig.
Die Daten werden dort als CSV Datei zur Verfügung gestellt. Details hier: Schweizer Ortschafts-Koordinaten.
Wie lädt man jetzt diese Daten in eine Datenbank?
Laden der Daten mit MariaDB/MySQL
MariaDB und MySQL haben dafür den Befehl LOAD DATA INFILE:
SQL> DROP TABLE IF EXISTS wgs84;
SQL> -- SET GLOBAL local_infile = ON; -- Only needed with MySQL
SQL> CREATE TABLE wgs84 (
ortschaftsname VARCHAR(32)
, plz4 SMALLINT
, zusatzziffer SMALLINT
, zip_id SMALLINT UNSIGNED
, gemeindename VARCHAR(32)
, bfs_nr SMALLINT
, kantonskuerzel CHAR(2)
, adressenanteil varchar(8)
, e DOUBLE
, n DOUBLE
, sprache VARCHAR(8)
, validity VARCHAR(12)
); …Taxonomy upgrade extras: csv, fdw, foreign data wrapper, postgresql, mysql, mariadb, copy, load data infile,
Attribute Promotion und Demotion im MariaDB Galera Cluster
In der MariaDB Master/Slave Replikation gibt es ein Feature welches sich Attribute Promotion/Demotion nennt.
Das kann man in etwa übersetzten mit Spalten Erweiterung/Einschränkung.
Einfach gesagt geht es darum, wie sich der Slave verhält oder verhalten soll, wenn Master und Slave unterschiedliche Spalten-Definitionen oder gar eine unterschiedliche Anzahl von Spalten oder eine Unterschiedliche Reihenfolge der Spalten aufweisen.
Use case des Kunden
Diese Woche haben wir mit einem Kunden den Fall diskutiert, wie er ein Rolling-Schema-Upgrade (RSU) in einem Galera Cluster ausführen könnte.
Bei früheren Schema-Änderungen hat er immer Probleme gekriegt was bis zum Totalausfall des Clusters für mehrere Stunden geführt hat.
Der Kunde meint, dass niemals Spalten gelöscht und neue Spalten immer nur am Ende einer Tabelle hinzugefügt werden.
Und das NICHT sichergestellt werden kann, dass wärend des Rolling-Schema-Upgrades keine schreibenden Verbindungen mehr existieren.
Verwendet wird das PHP ORM-Framework Doctrine.
Was …
Taxonomy upgrade extras: galera cluster, galera, replikation, mariadb,
Categories:
FromDual All (De)
FromDual TechFeed (De)
MariaDB Honeypot
Bei unseren MariaDB für Fortgeschrittene Schulungen, welche wir in etwa alle zwei Monate halten, verwenden wir Maschinen, welche mit einer öffentlichen IP-Adresse direkt dem Internet ausgesetzt sind. Achtung: Man sollte NIE eine Datenbank ungeschützt direkt dem Internet aussetzen! Typischerweise dauert es keine 72 Stunden (3 Tage) bis wir ersten Zugriffsversuchen von aussen ausgesetzt sind.
Dies sieht dann im MariaDB Error Log in etwa wie folgt aus:
[Warning] Aborted connection 22939 to db: 'unconnected' user: 'unauthenticated' host: '118.193.58.125' (This connection closed normally without authentication)
[Warning] Aborted connection 22940 to db: 'unconnected' user: 'unauthenticated' host: '118.193.58.125' (This connection closed normally without authentication)
[Warning] Access denied for user ''@'118.193.58.125' (using password: NO)
[Warning] Access denied for user 'root'@'118.193.58.125' (using password: YES)
[Warning] Access denied for user 'root'@'118.193.58.125' (using password: YES)
Zuerst wird …
Taxonomy upgrade extras: mariadb, honeypot, security,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Wie verhält sich Galera Cluster mit vielen Knoten?
Kürzlich hatte ich die Gelegenheit ganz viele Linux Systeme (VMs mit Rocky Linux 9) aus einer unserer regelmässig stattfindenden Galera Cluster Schulungen eine Woche lang ganz für mich alleine zur freien Verfügung zu haben. Und auf den Maschinen war auch schon ein MariaDB 11.4.4 mit Galera Cluster installiert.
Da ich schon lange mal ausprobieren wollte, wie sich ein Galera Cluster mit zunehmender Anzahl Knoten verhält, war jetzt die Gelegenheit dies mal auszuprobieren.
Die folgenden Fragestellung sollten beantwortet werden:
- Wie verhält sich der Durchsatz eines Galera Clusters in Abhängigkeit der Anzahl Galera-Knoten?
- Mit welcher Konfiguration erhalten wir den grössten Durchsatz?
Insgesamt wurde mit 5 verschiedenen Versuchs-Parameter experimentiert:
- Anzahl Galera Knoten.
- Anzahl Client Maschinen (= Instanzen).
- Anzahl Threads pro Client (
--threads=). - Anzahl Galera Threads (
wsrep_slave_threads). - Laufzeit der Tests. Dieser Parameter wurde variiert weil einige Tests während des Laufs abgebrochen sind. …
Taxonomy upgrade extras: galera, galera cluster, cluster, skalierbarkeit, durchsatz,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Spielen mit MariaDB Vector für erste KI-Tests
Künstliche Intelligenz (KI) und Vektor-Datenbanken sind heute in aller Munde. Da MariaDB demnächst auch mit Vektor-Datenbank-Funktionalität auf den Markt kommt, habe ich es als Datenbank-Berater für an der Zeit befunden mich etwas mit dem Thema zu beschäftigen, damit ich wenigstens einen Hauch Ahnung davon habe um was es geht…
Da ich nicht so der Theoretiker bin sondern eher gerne etwas praktisches mache, habe ich einen kleinen “KI” Prototypen gebaut, den jeder auf seinem Laptop (ohne GPU) sehr schnell und einfach nachbauen kann…
Ich habe mir auch erlaubt die Graphen aus dem Vortrag der MariaDB Foundation zu klauen (siehe Quellen am Ende).
Herunterladen der MariaDB Datenbank mit Vektor Funktionalität
Noch gib es keine MariaDB Pakete mit Vektor-Funktionalität, aber der Quellcode ist bereits verfügbar. Also baut man sich die Binaries halt schnell selber. Dies hat auf meiner alten Kiste eine knappe Stunde gedauert. Wenn die Binaries gebaut sind, kann man sich einen Tarball draus machen: …
Taxonomy upgrade extras: mariadb, ki, ai, vector, artificial intelligence, künstliche intelligenz, vektor,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Partieller physischer Datenbank-Restore für MariaDB und MySQL
Um was geht es?
Bei der Beschreibung von Backup- und /Restore-Szenarien wird in der Regel immer von einem vollständigen Backup (full backup) und einem vollständigen Restore (full restore) der Datenbankinstanz (mariadbd/mysqld) ausgegangen. Das bedeutet, dass die gesamte Datenbankinstanz inklusive aller Datenbanken (Schemata) gesichert und wiederhergestellt wird.
In der Praxis sieht die Situation jedoch oft anders aus: Es soll nicht eine ganze Datenbankinstanz wiederhergestellt werden, sondern nur einzelne Datenbanken oder gar einzelne Tabellen, weil nur diese kaputt gegangen sind.
Dies kann in vielen Fällen recht einfach mit den Tools mariadb-dump/mariadb oder mysqldump/mysql (logisches Backup) bewerkstelligt werden. Wenn die Datenbank oder die Tabelle jedoch sehr gross ist, wird die Wiederherstellung nicht in angemessener Zeit (einige Minuten bis wenige Stunden) abgeschlossen sein.
Genau in diesem Fall kommt der sogenannte partielle physische Restore ins Spiel. Partiell steht für eine oder mehrere Tabellen …
Taxonomy upgrade extras: partial restore, restore, database, schema,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Verkleinern des InnoDB-System-Tablespaces
Ein Feature, das mich im neuen MariaDB 11.4 LTS Release wirklich begeistert hat, ist das Verkleinern bzw. Schrumpfen des System-Tablespaces (ibdata1). Auf dieses Feature habe ich seit ca. 2006 sehnsüchtig gewartet und nun ist es mit MariaDB 11.4 endlich gekommen.
Eigentlich gibt es dieses Feature schon seit dem MariaDB 11.2 IR (Juni 2023).
Leider ist die Ankündigung dieses Features etwas zu kurz gekommen. In den MariaDB Release Notes heisst es lapidar:
The InnoDB system tablespace is now shrunk by reclaiming unused space at startup (MDEV-14795)
Die Gründe, warum dieses Datei ins Unermessliche wachsen kann, sind eigentlich schon lange bekannt und die Massnahmen dagegen sind auch klar (siehe Literatur). Nur sehen wir immer wieder MariaDB-Anwender draussen im Feld, die das Problem nicht oder zu spät auf dem Schirm hatten und nun mit einer viel zu grossen ibdata1-Datei da stehen…
Wie kann das Problem provoziert werden?
Das Problem kann provoziert werden, indem man …
Taxonomy upgrade extras: innodb, tablespace, ibdata1,
Categories:
FromDual All (De)
FromDual TechFeed (De)
dbstat für MariaDB nach einem Monat produktiver Nutzung
Inhaltsverzeichnis
- Rückblick
- Einen Monat später
- Grösse der Tabellen
- Prozessliste
- Globale Variablen
- Metadata Lock und InnoDB Transaction Lock
- Globaler Status
Rückblick
Nachdem wir vor gut 5 Wochen dbstat für MariaDB (und MySQL) vorgestellt haben, haben wir es natürlich auch auf unseren Systemen ausgerollt um das Verhalten im täglichen Einsatz zu testen (eat your own dog food).
Das ging soweit ganz gut, bis wir auf unserem MariaDB aktiv/passiv Master/Master Replikationscluster auf die Idee kamen, dbstat auch auf dem passiven dbstat Node zu aktivieren (eine ähnliche Situation hätte man auch bei einem Galera Cluster). Dabei stellten wir fest, dass das Design von dbstat noch Potential hatte. Nachdem dieses Problem behoben war (v0.0.2 und v0.0.3) und auch das Problem gelöst war, wie man Events auf Master UND Slave aktivieren kann (MDEV-33782: Event is always disabled on slave), schien auf den ersten Blick alles in Ordnung. Leider haben wir bei der Korrektur nicht bedacht, dass auch die Daten hätten angepasst …
Taxonomy upgrade extras: performance, monitoring, performance monitoring, metadata lock, locking, performance_schema,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Parallel replication
Nice story Oli, good to hear that enabling parallel replication was able to help quickly catch-up the 5 days lag.
Yes, it is often the case that a high number of threads can be beneficial. This is because transactions often need to wait for each other to ensure correct commit order and data consistency. And until we get a thread pool mechanism in parallel replication, waiting transaction equals waiting threads, unfortunately.
Interesting with the foreign key violation reports from InnoDB. This is probably just normal temporary errors caused by the optimistic apply in parallel of transactions that end up conflicting (eg. insert in child table runs before insert in parent). Such errors are silently handled on the server layer to roll back and retry the offending transaction. But maybe these should also be silenced in the InnoDB status information to not cause confusion (when the foreign key error is temporary and automatically handled by the parallel replication)?
Taxonomy upgrade extras:
Categories:
MariaDBs parallele Replikation zum Aufholen
Aufgrund eines applikatorischen Fehlers ist unsere Replikation während 5 Tagen stehen geblieben (über Ostern). Nachdem das Problem gelöst war, sollte die Replikation aufholen, was sich als sehr zäh herausstellte. All die üblichen Tricks (innodb_flush_log_at_trx_commit, sync_binlog, etc.) wurden bereits ausgereizt. Also haben wir uns an der parallelen Replikation des MariaDB Servers versucht.
Per default ist die parallel Replikation deaktiviert:
SQL> SHOW GLOBAL VARIABLES LIKE '%parallel%';
+-------------------------------+------------+
| Variable_name | Value |
+-------------------------------+------------+
| slave_domain_parallel_threads | 0 |
| slave_parallel_max_queued | 131072 |
| slave_parallel_mode | optimistic |
| slave_parallel_threads | 0 |
| slave_parallel_workers | 0 |
+-------------------------------+------------+
Durch setzen der Server Variablen slave_parallel_threads wird die parallele Replikation aktiviert: …
Taxonomy upgrade extras: replication, mariadb, parallel, multi-threaded,
Categories:
FromDual All (De)
FromDual TechFeed (De)
MariaDB Server aus den Quellen bauen
Kürzlich musste ich ein neues MariaDB Feature testen, welches auf unseren Wunsch entwickelt wurde (MDEV-33782). Um dieses Feature zu testen musste ich aber den MariaDB Server selber aus den Quellen bauen, was ich schon seit längerem nicht mehr gemacht habe. Also eine neue Herausforderung, insbesondere mit CMake…
I habe hierzu die MariaDB Dokumentation Get, Build and Test Latest MariaDB the Lazy Way befolgt um den Server zu bauen.
Auf Ubuntu 22.04 hat es bei mir, aus mir nicht bekannten Gründen, nicht funktioniert. Also habe ich mir einen Ubuntu 23.04 (Lunar Lobster) LXC Container geclont und darin den MariaDB Server gebaut.
Damit das ganze funktioniert musste aber vorher noch im Container /etc/apt/sources.list durch die Paketquellen ergänzt werden:
deb-src http://de.archive.ubuntu.com/ubuntu lunar main restricted universe multiverse
deb-src http://de.archive.ubuntu.com/ubuntu lunar-updates main restricted universe multiverse
deb-src http://de.archive.ubuntu.com/ubuntu lunar-security main restricted …Taxonomy upgrade extras: mariadb, build, compiling, sources, tarball,
Categories:
FromDual All (De)
FromDual TechFeed (De)
MaxScale Konfigurations-Synchronisation
Inhaltsverzeichnis
- Übersicht
- Vorbereitungen
- MaxScale Konfigurations-Synchronisation aktivieren
- MaxScale Parameter ändern
- Neuer Slave hinzufügen und MaxScale bekannt machen
- Alter Slave entfernen und MaxScale bekannt machen
- Wie wird die Konfiguration synchronisiert?
- Was passiert im Konfliktfall?
- Tests
- MaxScale Konfigurations-Synchronisation wieder deaktivieren
- Literatur/Quellen
Übersicht
Ein Feature, welches ich beim Stöbern kürzlich entdecke habe, ist die MaxScale Konfigurations-Synchronisation Funktionalität.
Es geht hier nicht primär um einen MariaDB Replikations-Cluster oder einen MariaDB Galera Cluster sondern um einen Cluster bestehend aus zwei oder mehreren MaxScale Knoten. Bzw. etwas genauer gesagt, den Austausch der Konfiguration unter diesen MaxScale Knoten.
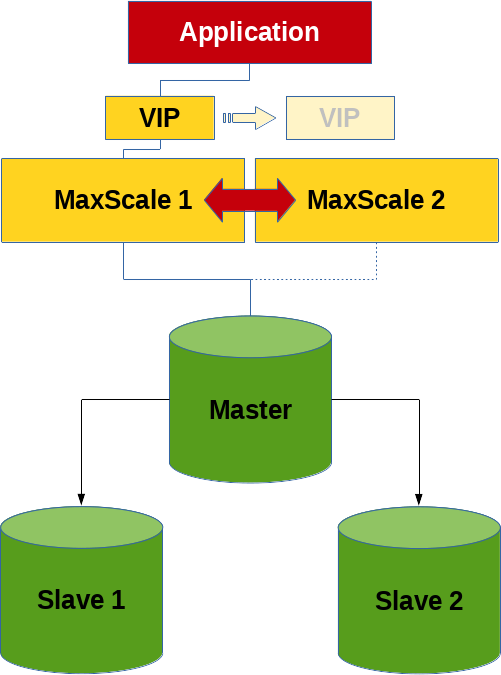
Pon Suresh Pandian hat bereits 2022 einen Blog-Artikel über dieses Feature geschrieben, der noch etwas ausführlicher ist, als dieser Beitrag hier.
Vorbereitungen
Es wurde eine Incus Container-Umgebung vorbereitet, bestehend aus 3 …
Taxonomy upgrade extras: maxscale, configuration, cluster, load balancer,
Categories:
FromDual All (De)
FromDual TechFeed (De)
Sharding mit MariaDB MaxScale
Inhaltsverzeichnis
- Übersicht
- Vorbereitung der Shards (MariaDB Datenbank Instanzen)
- MaxScale SchemaRouter Konfiguration
- Starten und Stoppen des MaxScale Load Balancers
- Applikations-Tests
- Betrieb eines MaxScale Sharding-Systems
- Beobachtung / Observierung eines MariaDB MaxScale Sharding-Systems
- Literatur / Quellen
Übersicht
Dieses Feature sollte mehr oder weniger mit MariaDB MaxScale 6.x.y, 22.08.x, 23.02.x, 23.08.x und 24.02.x funktionieren. Wir haben es …
Taxonomy upgrade extras: sharding, maxscale, schemarouter, load balancer, multi-tenant,
Categories:
FromDual All (De)
FromDual TechFeed (De)
